
Pipeline
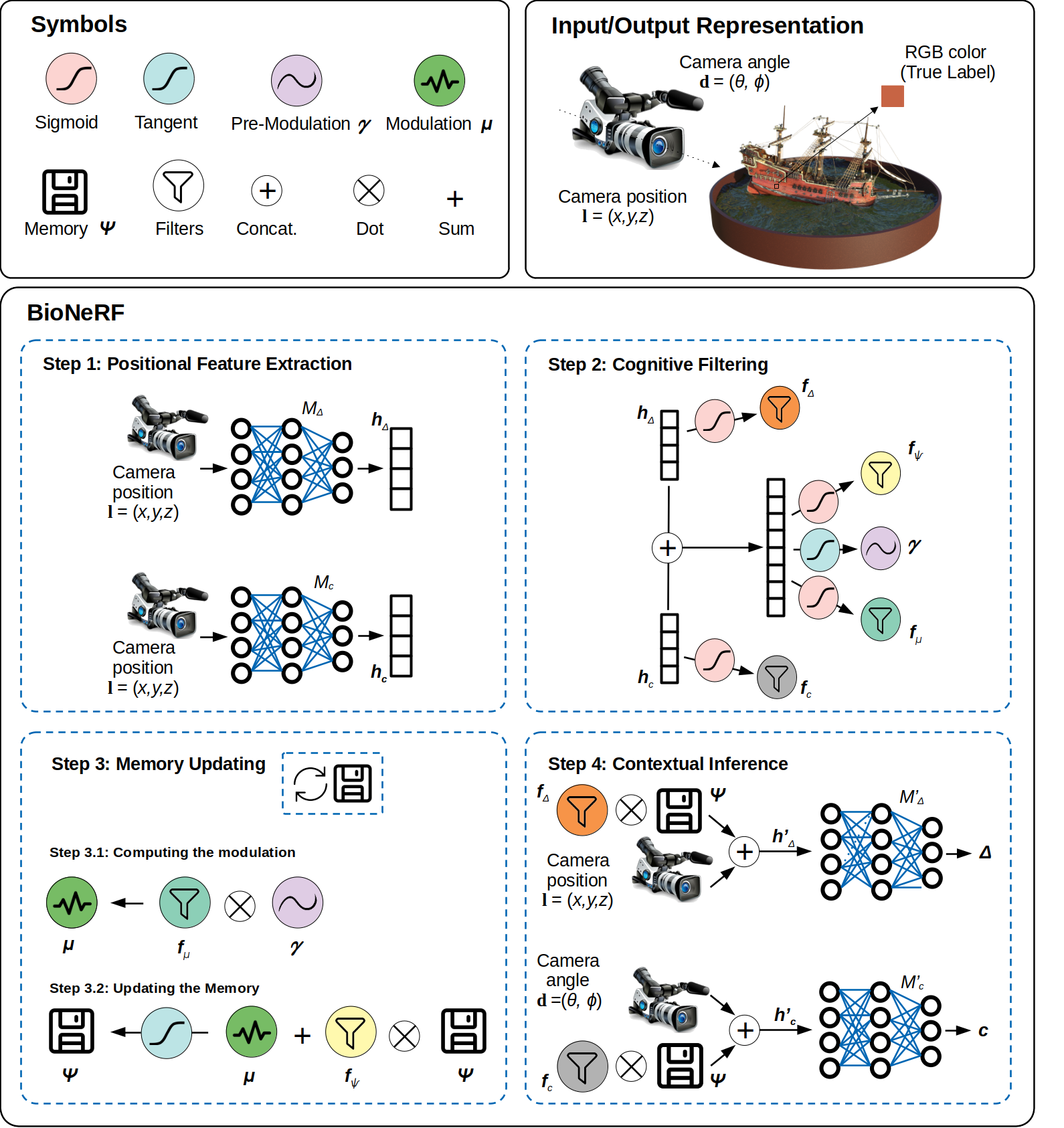
Here is an overview pipeline for BioNeRF, we will walk through each component in this guide.
Positional Feature Extraction
The first step consists of feeding two neural models simultaneously, namely
Cognitive Filtering
This step performs a series of operations, called filters, that work on the embeddings coming from the previous step. There are four filters this step derives: density, color, memory, and modulation.
Memory Updating
Updating the memory requires the implementation of a mechanism capable of obliterating trivial information, which is performed using the memory filter (Step 3.1 in the figure). Fist, one needs to compute a signal modulation
Contextual Inference
This step is responsible for adding contextual information to BioNeRF. Two new embeddings are generated, i.e.,

